Kafka消息系统教程
东南亚Grab如何降低Kafka流量成本?

Grab 是东南亚领先的超级应用平台,提供对消费者重要的日常服务。Grab 不仅仅是一款叫车和送餐应用程序,还在该地区提供广泛的按需服务,包括移动、食品、包裹和杂货配送服务、移动支付以及遍及 8 个国.
Spring Modulith:模块内领域事件发给外部Kafka的示例

使用spring modulith轻松地将选定的域事件外部化到消息代理:添加例如,Kafka集成模块选择要外部化的域类型(例如,通过使用(At)外部化)点击标题见案例,展示如何自动将域事件外部化到 K.
将Kafka和Zookeeper通过Quarkus和GraalVM编译为本地快速启动的原生代码

使用kafka-native可以将Kafka 代理(和 Zookeeper)通过Quarkus 和 GraalVM 编译为本机原生代码。项目结构 quarkus-kafka-server-extens.
使用 Vert.x 处理 Kafka 和数据库之间的背压
异步编程在开发反应式和响应式应用程序方面带来了许多优点。然而,它也存在缺点和挑战,其中主要的问题之一是背压问题。什么是背压?在物理学中定义是:它是与管道中所需的流体流动相反的阻力或力我们可以把这个问题.
Spring Boot Kafka 生产者和消费者示例

在本节教程中,我们将学习如何在 Spring Boot Kafka 项目中创建 Kafka Producer 和 Consumer 。Spring 团队 为 Apache Kafka 依赖项提供 S.
跨微服务共享公共数据如何实现?
在微服务设计过程中,经常出现的一个共同点和要求是共享共同数据。而这个问题在微服务之间的异步消息驱动通信(使用Kafka)中变得更加有趣了例如,微服务1有一些数据。微服务2和3想要访问这些数据。我看到了.
使用Kafka并行消费者提高Apache Kafka性能

与其他现代大数据平台一样,Kafka 通过将数据分区到集群中的多个节点来实现无限的水平可扩展性。对于 Kafka,这意味着每个主题都有 1 个或多个分区。主题拥有的分区越多,并发性就越高,因此潜在的吞.
Kafka的关键配置min.insync.replicas

Kafka的关键配置min.insync.replicas :用户消息生产的客户端配置,表示消息生产者认为写入成功之前确认收到记录的代理数量。 - acks==0 — 发送请求时认为写入成功 - 无需.
Apache Kafka能用于工作流编排引擎吗?
BPMN或类似的流程图很适合于业务流程的建模。业务和技术团队很容易理解可视化的内容。它记录了业务流程,便于以后的修改和重构。各种工作流引擎解决了自动化问题:BPMS,RPA工具,ETL和iPaaS数据.
《KIP-932:Queues for Kafka》于7天前发布。
Kafka的队列Queues 是目前讨论的最热门的新功能!传统的队列系统是这样一种系统: - 多个消费者从同一队列读取(pub-sub) - 一个特定的消费者从一个特定的生产者读取(点对点) 消息通常.
使用Kafka 和 Spring Boot 实现并发编程
本文将教您如何使用 Spring Boot 和 Spring for Kafka 为 Kafka 消费者配置并发。Spring for Kafka 的并发与Kafka 分区和消费者组密切相关。消费者组.
在没有 zookeeper 的情况下运行 Kafka

Kafka在其 Kafka Raft Metadata 模式中使用 Raft 共识算法进行领导者选举,从而消除了对 ZooKeeper 管理集群元数据的依赖。Raft算法是一种共识协议,旨在确保分布式.
使用 Knative、Quarkus 和 Kafka 在 OpenShift 上实现无服务器
在 OpenShift 上构建和运行 Quarkus 无服务器应用程序,并通过 Knative Eventing 集成它们。我们将使用 Kafka 在应用程序之间交换消息。Knative 支持各种事件.
为什么 Apache Kafka 不需要 Fsync 来保证安全?

Apache Kafka 不需要 fsyncs 来确保安全,因为它在其复制协议中包含恢复。它是一个真实世界的分布式系统,使用异步日志写入 + 恢复,并内置一些额外的额外安全性。异步日志写入使其能够在各.
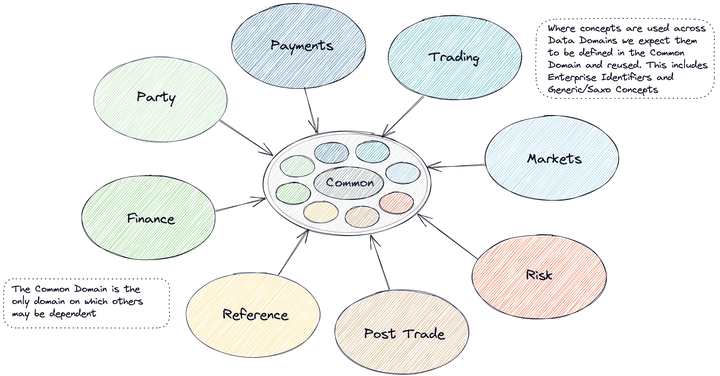
盛宝银行基于数据网格的分布式领域驱动架构最佳实践
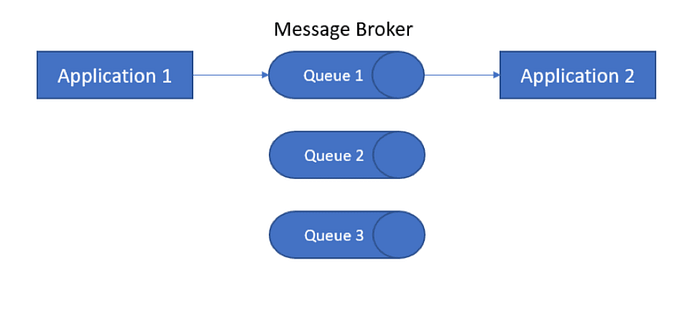
Redis、Kafka 与 RabbitMQ 对比
Bitcask - 日志结构的快速 KV 存储

Bitcask 是最高效的嵌入式键值 (KV) 数据库之一,旨在处理生产级流量。向世界介绍 Bitcask 的论文称它是一个用于快速键/值数据的日志结构 哈希表,用更简单的语言来说,这意味着数据将按顺.
ActiveMQ 与 Kafka 的比较 | redhat

将 ActiveMQ 与 Kafka 进行比较类似于将关系数据库与 NoSQL 进行比较。ActiveMQ 不像 Kafka 那样适合云。但这并不意味着 ActiveMQ 不再有任何用例。仍然有大量业.
如何探测不健康 Kafka 消费者并将其自动重启?
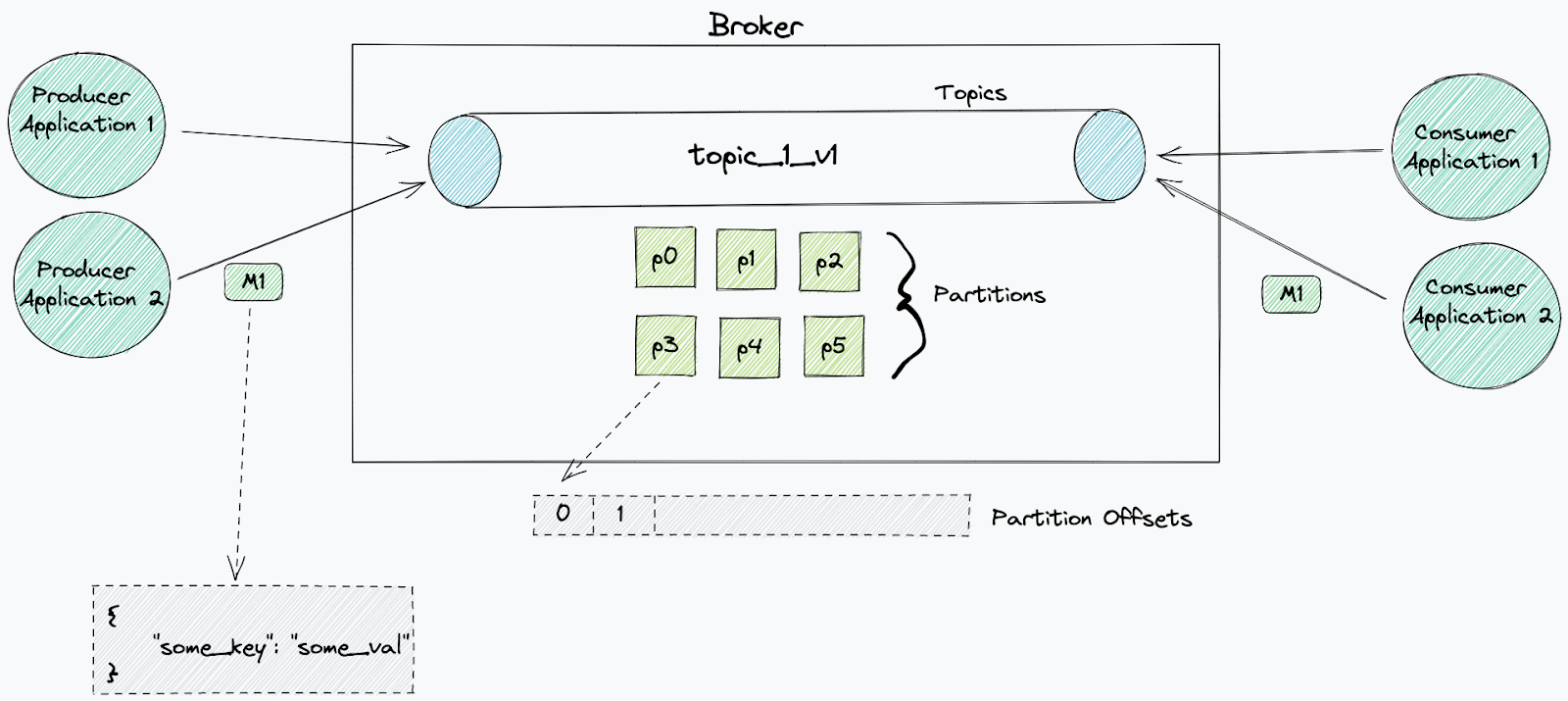
Kafka 如何实现低延迟? - foojay

大多数 Apache Kafka 基准测试似乎测试的是高吞吐量而不是低延迟。Kafka 传统上用于高吞吐量而不是对延迟敏感的消息传递,但它确实具有低延迟配置:(主要是设置 linger.ms=0 并减.
Apache Kafka在实时物流、运输行业运用

物流、航运和运输需要实时信息来构建高效的应用程序和创新的业务模型,通过数据流支持相关的决策、建议和警报。这篇博文探讨了 Kafka在USPS、瑞士邮政、奥地利邮政、DHL 和 Hermes 等公司的几.
使用Flink实现Exactly-Once分布式事务 - Devora

一切都使用 Postgres
如何降低复杂性并加快行动速度? 使用 Postgres 作为消息队列跳过锁定而不是 Kafka(如果你只需要一个消息队列)。 使用 Postgres时标Timescale作为数据仓库。 使用 Post.
Apache Flink与Kafka Streams区别? - Gunnar
Apache Flink与Kafka Stream都能实现流处理,但在一些重要方面有所不同。下面是从用户的角度出发的,不涉及实现细节:支持的流平台不同 作为的Apache Kafka项目的一部分,Ka.
将数据库更改复制到消息队列很棘手 (evanjones.ca)
假设我们有一个将其状态存储在数据库中的程序,我们希望其他程序在发生变化时做一些事情。例如,我们可能想在银行余额下降到某个阈值以下时发送电子邮件通知。这是应用程序使用Kafka等消息队列的一个非常常见的.
删除Kafka无用主题可提升40%性能
linkedin启动TopicGC删除Kafka不用的topic后,已经删除了近20%的topic,大大降低了Kafka集群的元数据压力。客户端请求性能提高了 40% 左右,CPU 使用率降低了 30.
covrom/redispubsub:Redis Streams的发布订阅驱动程序

Go语言·的package pubsub 提供了一种简单且可移植的方式来与发布/订阅系统进行交互。这个项目驱动是基于pubsub的Redis 驱动程序,使用 Redis Streams,此驱动程序支持.
Apache Kafka 12个最佳实践

Apache Kafka,也被称为Kafka,是一个企业级的消息传递和流媒体代理系统。Kafka是一项伟大的技术,可用于架构和建立实时数据管道和流媒体应用程序。我强烈建议架构师们熟悉Kafka生态系统.
基于CDC实现源数据库和派生数据库之间的强数据一致性

在源数据库和派生数据库之间保持强数据一致性对于基于CDC的流数据管道至关重要。目标数据库必须反映对源数据库所做的最新更改,因为数据更改速度很快。像Apache Pinot这样的实时OLAP数据库利用其.
schema_registry_converter:使用Rust编写的Kafka Schema Registry
消息是作为记录存储在 Kafka 上:记录有一个值和一个可选的键,它们都是二进制格式。另一个重要的事实是 Kafka 使用主题来拆分消息。一个主题可能存在多个主题分区,用于使其可扩展。部分配置是特定于.